
Hi! My name is Muyao Li (李沐遥). I am an undergraduate student in the Tong Class at Peking University, and currently an intern in the CraftJarvis team. You can reach me at li_muyao@stu.pku.edu.cn.
My research focuses on building generalized agents that unify perception, reasoning, and decision-making within an end-to-end foundation model. My current work centers on deploying such agents in games.
Research Interests: Machine Learning, Reinforcement Learning, Reasoning, Embodied Intelligence, LLM Agents
🔥 News
- 2025.05: 🎉🎉 The Paper “JARVIS-VLA: Post-Training Large-Scale Vision Language Models to Play Visual Games with Keyboards and Mouse” are accepted by ACL 2025
📝 Publications
ACL 2025
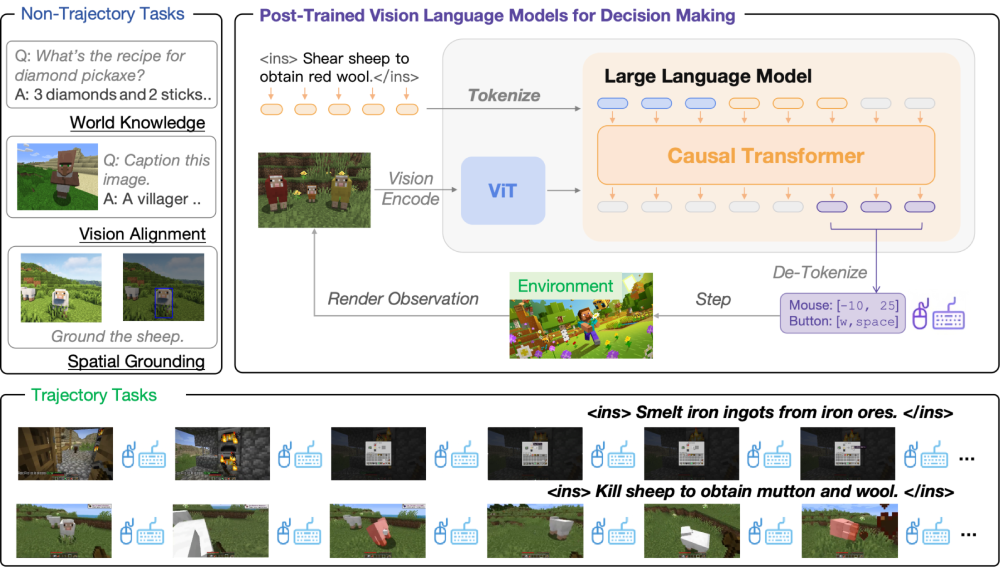
Muyao Li*, Zihao Wang, Kaichen He, Xiaojian Ma, Yitao Liang
- The first VLA models in Minecraft that can follow human instructions on over 1k different atomic tasks
- Introduce a novel approach, Act from Visual Language Post-Training, which refines Visual Language Models (VLMs) through visual and linguistic guidance in a self-supervised manner.
📖 Educations
 2022.09 - now, Undergraduate, Yuanpei College, Peking University, Beijing
2022.09 - now, Undergraduate, Yuanpei College, Peking University, Beijing